[GCP 원데이] Artillery를 사용한 부하 테스트
1. Artillery
1) 설치
brew install node
node -v
2) GCP 애플리케이션 실행
이전에 만들어둔 cpu-bound-application을 실행시켜준다.
java -jar cpu-0.0.1-SNAPSHOT.jar
3) Artillery 설정
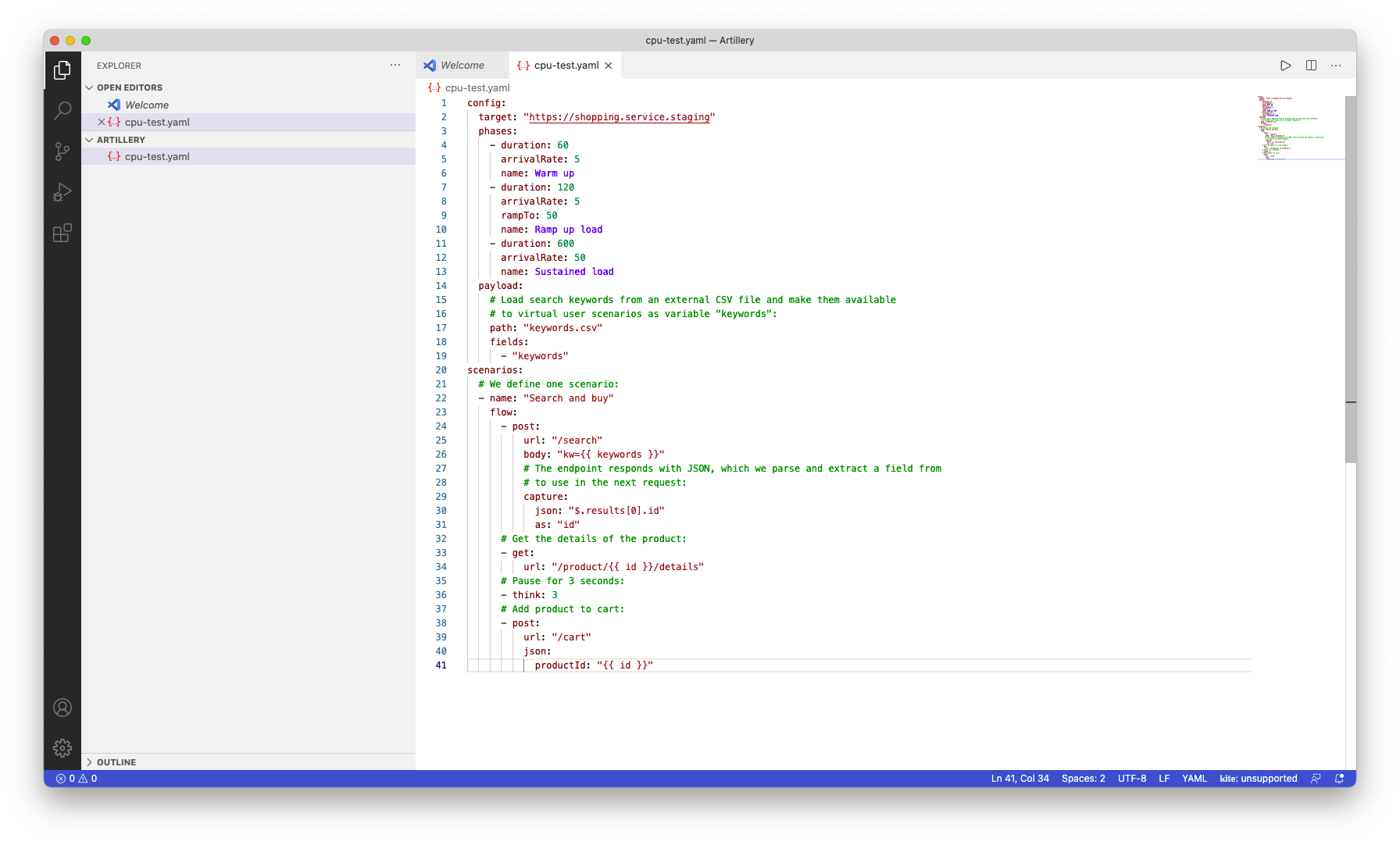
IP 주소를 복사하여 Artillery 스크립트의 target에 넣어주고 불필요한 부분을 삭제해준다.
config:
target: "http://[IP 설정]"
phases:
- duration: 60
arrivalRate: 1
name: Warm up
scenarios:
# We define one scenario:
- name: "just get hash"
flow:
- get:
url: "/hash/123"
여기서 phases는 도큐먼트 기준으로 300초 동안 성능을 측정하고 매초 10명의 가상의 유저를 만드는 설정이다.
phases:
- duration: 300 # 기간
arrivalRate: 10 # vuser(가상 유저)
name: Warm up4) Artillery 실행
이 후 Artillery를 실행시켜준다. (시간 소요)
artillery run --output report.json ./cpu-test.yaml
5) report.json
HTML 파일로 만들어준다.
artillery report ./report.json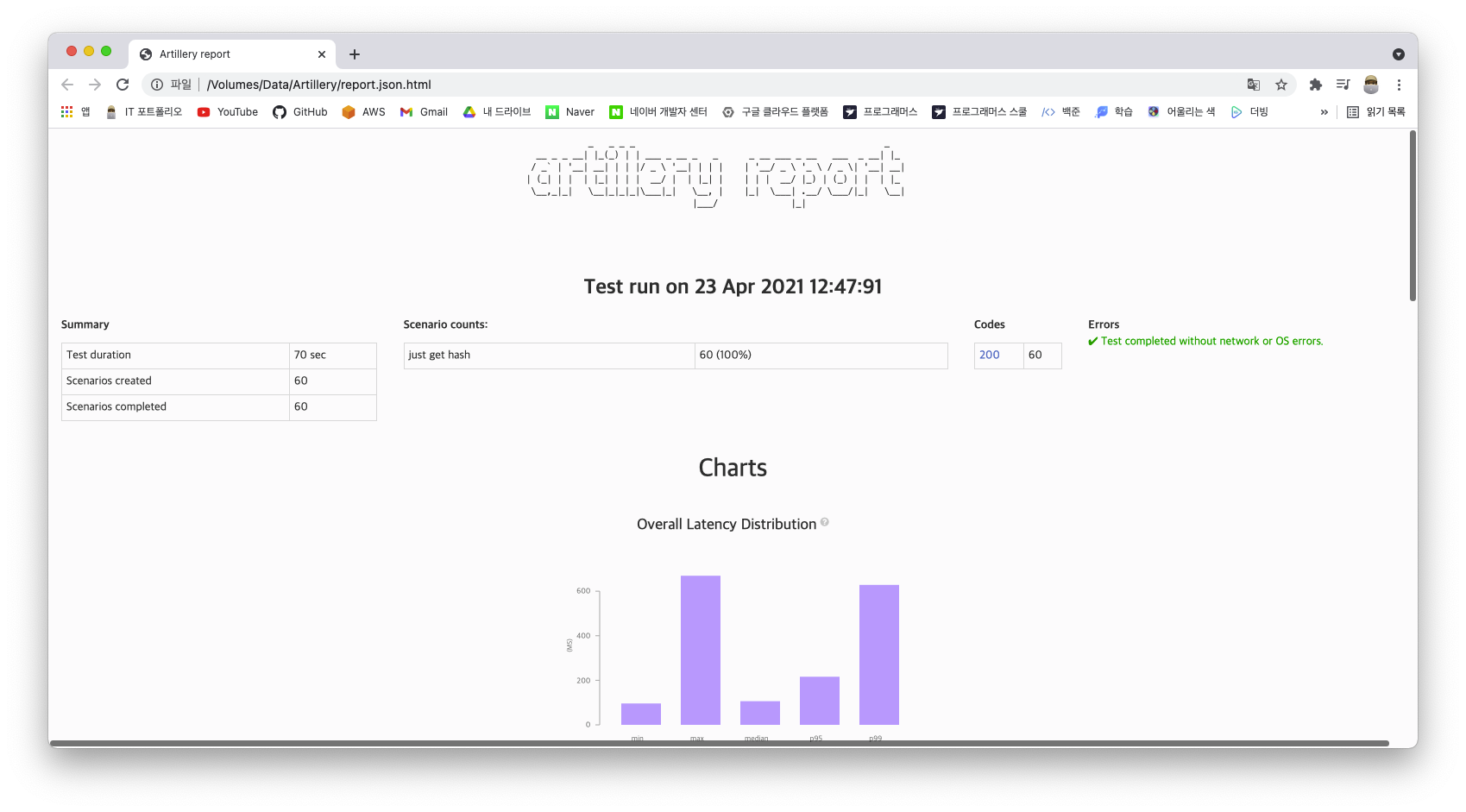
60초 동안 vuser를 1초에 한 번씩만 생성해주었기 때문에 1분동안은 60개의 Request가 전송되는 것을 알 수 있다.
6) Latency At Intervals
결과에 나온 항목들 중에서는 Latency At Intervals를 잘 살펴보아야한다.
앞서 설정한 스크립트대로라면, 서버에 적은 요청을 하고 있기 때문에 여유롭게 처리할 수 있다. 하지만 스크립트의 arrivalRate를 증가시키면 Latency At Intervals 차트의 변화를 확인할 수 있다.
arrivalRate를 8로 설정했을 때, 60초를 기점으로 뒤로갈 수 록 모든 요청들의 Latency At Intervals 항목의 Latency가 급격하게 증가하는 것을 확인할 수 있다. 즉, 8명의 vuser를 처리할 수 없는 상태가 된다. 심지어 에러가 생기는 것도 확인할 수 있으며, 이 에러는 시간이 지날수록 더 늘어난다.
config:
target: "http://[IP 설정]"
phases:
- duration: 60
arrivalRate: 8
name: Warm up
scenarios:
# We define one scenario:
- name: "just get hash"
flow:
- get:
url: "/hash/123"

Latency가 0으로 갈 수록 응답이 짧은 시간안에 왔다는 것이다. 그래프의 각 선이 의미하는 바는 다음과 같다.
- max - 가장 오래 걸린 요청 (응답 시간)
- p95 - 전체 HTTP 트랜잭션 중 가장 빠른 것부터 95%까지 (거의 대부분의 트래픽이 해당)
- p50 - 전체 HTTP 트랜잭션 중 가장 빠른 것부터 50%까지 (절반의 트래픽이 해당)
- min - 가장 빠르게 온 요청 (응답 시간)
실제로 벤치마킹을 하는 것은 p99와 p95이다. p99는 거의 대부분의 트래픽이 해당되기 때문에 실제 애플리케이션의 성능이라고 생각하면 된다. max는 불안정한 네트워크상에서 지연시간이 발생하는 경우가 있기 때문에 성능 측정 결과에 영향을 미치는 것이 좋지 않아 사용하지 않는다.
7) 성능 측정
만약 자신이 만든 API의 성능을 측정한다면, 목표로하는 Latency를 잡아주어야 한다. 만약 만족하지 않은 결과가 나올 경우 CPU가 더 많은 서버로 스케일업을 하거나 nginx로 로드밸런싱을 이용해 해결해야한다.
8) 스케일 아웃 (CPU)
서울 리전에서 8개의 CPU를 생성하기에는 제한이 있기 때문에 기존에 만든 인스턴스를 삭제하고 다시 생성해주도록 한다. 기존에 생성한 인스턴스와의 차이점은, CPU의 개수이다.
이 후 동일한 과정을 거쳐 스크립트를 실행하면, 기존의 Latency At Intervals 항목이 훨씬 안정적인 그래프가 나오는 것을 확인할 수 있다. 중간에 급격하게 증가한 이유는, VM이 인접하고 있는 인스턴스들과 자원을 공유하기 때문이다.
※ 생성한 VM 인스턴스는 과금될 소지가 있기 때문에 바로 삭제해주어야 한다.
9) 현업의 스케일 아웃 기준
1. 예상 TPS보다 여유롭게 성능 목표치를 잡아야한다.
만약 예상 TPS가 1000정도라면 트래픽이 튀는 상황을 대비해 최소 3천에서 4천 이상으로 여유롭게 인스턴스를 구성해야한다. 많으면 많을 수록 좋지만, 그 만큼 서버 비용도 과금이 된다.
2. 기대 Latency를 만족할 때까지 성능을 테스트하고, 스케일아웃을 해도 성능이 늘지 않으면 다른 이유를 의심해야한다.
가장 먼저 단일 요청에 대한 Latency가 몇인지 확인해보고, 단일 요청에 대한 Latency가 기대하는 Latency 보다 높으면 스케일 아웃으로 해결할 수 없는 문제이다. 대부분 이런 경우 코드가 비효율적으로 작성되었거나 해당 API에서 실행되는 I/O가 병목인 경우가 많다. 네트워크에서 Latency가 발생하는 경우도 있기에 다양한 상황을 확인해보아야한다.