2020. 10. 5. 16:12ㆍDatabase/Redis
1. Expire
Redis는 데이터에 대해 생명주기를 정해서 일정 시간이 지나면 자동으로 삭제되게 할 수 있다. Redis가 expire된 데이터를 삭제하는 정책은 내부적으로 Active와 Passive 방식이 존재한다. Active 방식은 클라이언트가 expire된 데이터에 접근하고자 할 때, 체크해서 지우는 방법이고, Passive 방식은 주기적으로 키들을 랜덤으로 100개만 스캔해서 지우는 방식이다.
만료시간이 지난 후 클라이언트에 의해서 접근 되지 않은 데이터는 Active 방식으로 인해서 지워지지 않고 Passive 방식으로 지워져야 하는데, 이 경우 전체 데이터를 스캔하는 것이 아니기 때문에 Redis에는 항상 expire 되었으나 지워지지 않는 가비지 데이터가 존재할 수 있는 원인이 된다.
2. Persistence
1) Persistence
Redis는 memcached와 달리 디스크에 저장할 수 있다. 저장이 가능하기에 비정상적으로 서버가 종료되더라도 디스크에 저장해놓은 데이터를 다시 읽어 메모리에 로딩하기 때문에 데이터 유실이 없다. 데이터를 저장하는 방식은 크게 RDB방식과 AOF 방식이 존재한다.
2) RDB (Snapshotting)
순간적으로 메모리에 있는 내용을 디스크에 전체를 옮겨 담는 방식이다. SAVE와 BGSAVE 두가지 방식이 존재한다. SAVE는 Blocking 방식으로 순간적으로 Redis의 모든 동작을 정지시키고 그때의 스냅샷을 디스크에 저장하고, BGSAVE는 Non-Blocking 방식으로 별도의 프로세스를 띄워 명령어 수행 당시의 메모리 스냅샷을 디스크에 저장하여 저장 순간에 Redis의 동작을 멈추지 않도록 한다.
서버 재시동시 스냅샷만 로딩하면 되기에 재시동 시간이 빠르지만 스냅샷을 추출하는데 시간이 오래걸리며 백업 시점의 데이터만 유지되기에 백업 이후의 데이터는 유실된다.
3) AOF (Append On File)
Redis의 모든 쓰기, 업데이트 연산 자체를 모두 로그 파일에 기록하는 형태이다. 서버가 재시작될 때 기록된 write, update 연산을 순차적으로 재실행하여 데이터를 복구한다. 연산이 발생할 때마다 매번 기록하기 때문에 RDB와는 다르게 특정 시점이 아닌 항상 현재 시점까지의 로그를 기록할 수 있으며 기본적으로 Non-Blocking Call이다.
로그 파일에 대해서 Append만하기 때문에 로그 write 속도가 빠르며, 어느 시점에 서버가 종료되더라도 데이터 유실이 발생하지 않지만 모든 write, update 연산에 대해서 로그를 남기기 때문에 로그 데이터양이 RDB 방식에 비해 과대하게 크며, 복구시 저장된 write, update 연산을 다시 수행하기에 재시작 속도가 느리다.
4) 권장 사항
RDB와 AOF 방식의 장단점을 상쇄하기 위해 두 가지 방식을 혼용해서 사용하는 것이 바람직하다. 주기적으로 스냅샷으로 백업하고 다음 스냅샷까지의 저장을 AOF 방식으로 수행하는 방식이 좋다.
3. Pub/Sub Model
사전적 의미로는 메시지를 보내고 받는 형태의 통신으로 해석된다. Redis는 JMS나 IBM MQ같은 메시징에 활용할 수 있다. 1:1형태의 Queue 뿐만 아닌 1:N 형태의 Publish/Subscribe(Topic) 메시징도 지원한다. 하나의 클라이언트가 메시지를 Publish하면, 이 Topic에 연결된 다수의 클라이언트가 메시지를 받을 수 있는 구조이다. 일반적인 Pub/Sub 시스템의 경우 Subscribe 하는 하나의 Topic에서만 Subscribe하는데 반해서, Redis는 Pattern Matching을 통해 다수의 Topic에서 메시지를 Subscribe할 수 있다.


4. Replication Topology
1) Replication Topology
Redis는 2.4.15버전 기준으로는 NOSQL 계열의 키-값 스토리지인데도 횡적 확장성을 지원하지 않는다. 즉, 클러스터링 기능이 없다. 따라서 확장성과 성능에 제약사항이 존재하지만, Master/Slave 구조의 Replication을 지원하기 때문에 성능 부분에서는 커버가 가능하다.
2) Master/Slave Replication
Master/Slave Replication은 Redis의 Master 노드에 write가 된 내용을 Slave 노드에 복제하는 것이다. 1개의 Master 노드에는 N개의 Slave 노드를 가질 수 있으며, Slave 노드 또한 그에 대한 Slave 노드를 가질 수 있다.
Master/Slave 간의 복제는 Non-Blocking 상태로 이루어진다. Master 노드에서 write나 쿼리 연산을 수행하고 있을 때도 백그라운드로 Slave 노드에 데이터를 복사할 수 있으며, 이는 Master/Slave 노드 간의 데이터 불일치성을 유발할 수 있다. Master 노드가 write가 된 내용을 Slave 노드에 복제중이라면 Slave 노드에서 데이터를 조회할 경우 이전 데이터가 조회될 수 있다.

3) Query Off Loading을 통한 성능 향상
Master/Slave Replication을 통해서는 Query Off Loading을 이용하여 성능을 높일 수 있다. 데이터 저장 용량이 아닌 동시 접속자 수나 처리 속도를 늘릴 수 있다. 이 기법은 Master는 write only, Slave는 read only으로 사용하는 방법이다 (Redis에서만 사용하는 기법이 아닌 Oracle, MySQL과 같은 RDBMS에서도 많이 사용하는 아키텍처 패턴).
대부분의 DB 트랜잭션은 웹 시스템의 경우 write가 10 - 20%, read가 70 - 90% 선이기 때문에 read 트랜잭션을 분산시킨다면 처리 시간과 속도를 비약적으로 증가 시킬 수 있다. 특히 Redis의 경우 값에 대한 여러가지 연산(합집합, 교집합, 범위 쿼리 등)을 수행하기 때문에 단순 PUT, GET만 하는 NOSQL이나 Memcached에 비해, read에 사용되는 리소스의 양이 상대적으로 높기 때문에 Redis의 성능을 높이기 위해서 효과적인 방법이다.
4) Shading을 통한 용량 확장
Redis가 클러스터링을 통한 확장성을 제공하지 않을 경우, 데이터의 용량이 늘어날 때에는 Shading 아키텍처를 이용하면 된다. 일반적인 RDBMS나 다른 NOSQL에서도 많이 사용하는 아키텍처이다. 여러개의 Redis 서버를 구성한 뒤에 데이터를 일정 구역별로 나눠서 저장하는 것이다.
예시로, 숫자를 키로 하는 데이터가 있을 때, Redis 서버별로 저장하는 키 대역폭을 정해놓은 후에 나눠서 저장한다. 데이터 분산에 대한 통제권은 클라이언트가 가지며, 클라이언트에서 애플리케이션 로직으로 처리한다.

4. Replication
1) Replication 과정
Redis는 Master - Replica 형태의 복제를 제공한다. 복제 연결이 되어있는 동안 Master 노드의 데이터는 실시간으로 Replica 노드에 복사된다. 따라서 서비스를 제공하던 Master 노드가 다운되더라도 Replica 노드에 애플리케이션을 재연결해 주면 서비스를 계속할 수 있다.

한 개의 Master에 여러 개의 Replica 노드가 붙을 수 있고, Replica 노드에 또 다른 Replica 노드가 연결되는 것도 가능하다. 하지만 한 개의 복제그룹에서는 항상 한 개의 Master 노드만 존재한다. 다중 Master의 구조로 양쪽으로 데이터를 복제하는 등의 구조는 불가능하다. 복제 방법은 Master 노드의 IP가 127.0.0.1, 포트가 6001이라면 Replica 노드에서 단순히 'replicaof 127.0.0.1 6001' 명령어를 실행하면 복제가 바로 시작된다.
replicaof 명령어를 받은 Master 노드 A는 자식 프로세스를 만들어 백그라운드로 덤프 파일을 만들고, 이를 네트워크를 통해 Replica 노드인 B에 보낸다. 이 파일을 받은 노드 B는 데이터를 메모리로 로드한다.

일단 연결이 되면, 데이터 복제는 비동기 방식으로 이루어진다. 즉, Master에 데이터가 들어오면 Master는 애플리케이션에 ACK를 보낸다. 그 다음 Replica 노드에 데이터를 전달하기 때문에, 만약 Master까지만 데이터가 입력된 후 Master 노드가 죽는다면 이 데이터는 Replica 노드까지 전달되지 않고 유실될 가능성이 존재한다. 현재는 이 현상을 디버깅 하기 힘들 정도로 데이터의 전달 속도가 매우 빠르기 때문에 유실은 빈번하게 발생되지 않을 것이라 예상된다.

2) Sentinel
외부의 HA 기능과 Redis Persistence 기능을 사용하지 않았을 경우, Redis 프로세스가 다운되면 메모리 내에 저장된 데이터는 유실된다. Master 노드에 연결된 Replica 노드가 있을 경우 그 데이터는 Replica 노드에 남아있다. 하지만 운영중인 서비스에서 애플리케이션이 Master에 연결된 상태였다면 3가지의 과정을 수행하게 된다.
1. Replica 노드에 접속하여 'replicaof no one' 명령어를 통해 Master 연결 해제
2. 애플리케이션 코드에서 Redis 연결 설정을 변경 (Master 노드 IP를 Replica 노드 IP로 변경)
3. 배포
실제 운영되는 서비스에서 이를 해결하기까지는 오랜 시간이 걸리며 이 기간 동안 데이터가 유실될 수도 있다. 애플리케이션이 Master 노드에 접근할 수 없을 때 데이터를 가져오기 위해 갑자기 많은 커넥션이 RDBMS에 몰려 서비스 장애로까지 이어지 사례도 존재한다.
이러한 인 메모리 데이터베이스의 장애를 해결하기 위해 도와주는 것이 Sentinel이다. Sentinel은 Master와 Replica 노드를 계속 모니터링하며, 장애 상황에는 Replica 노드를 Master로 승격시키기 위해 자동 Failover를 진행합니다. 특정 상황에 담당자에게 메일을 보내도록 알림(Notification)을 설정하는 것도 가능하다.
정상적인 기능을 위해서는 적어도 세 개의 Sentinel 인스턴스가 필요하다. 각 Sentinel 인스턴스는 Redis의 모든 노드를 감시하며 서로서로 연결되어 있다. 세 대의 Sentinel 노드 중 과반수 이상(quorum)이 동의해야만 Failover를 시작할 수 있다.
이러한 구성에서 애플리케이션은 Master나 Replica 노드에 직접 연결하지 않고, Sentinel 노드와 연결합니다. Sentinel 노드는 애플리케이션에게 현재 Master의 IP, PORT를 알려주며, Failover 이후에는 새로운 Master의 IP, PORT 정보를 알려준다.

3) Sentinel Failover 과정
Master에 두 개의 Replica 노드가 연결되어 있다고 가정한다.

이 때 Master가 다운되면 이를 감시하고 있던 Sentinel은 Master에 진짜 연결할 수 없는지에 대한 투표를 시작한다.
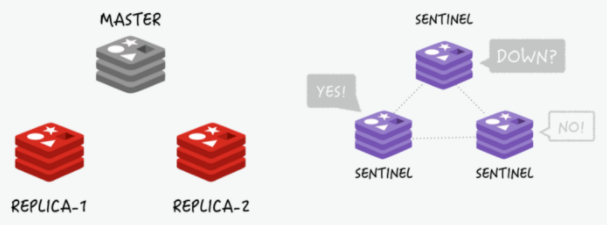
이 투표에서 과반수 이상이 동의하면 Failover를 시작합니다. 이 예제에서는 세 개 중 두 개 노드의 찬성을 얻어 Failover가 가능하다. 연결이 안되는 Master에 대한 복제연결을 끊고, Replica 노드 중 한 개를 선택하여 Master로 승격시킵니다.

또 다른 Replica 노드는 승격된 Master 노드에 연결시킵니다. 만약 다운되었던 Master 노드가 다시 살아난다면 새로운 Master에 복제본으로 연결됩니다.
4) 클러스터 (Cluster)
Redis 클러스터는 데이터셋을 여러 노드에 자동으로 분산하는 확장성 및 고성능의 특징과, 일부 노드가 다운되어도 계속 사용 가능한 고가용성의 특징을 가지고있다. 외부 프록시나 도구를 사용하지 않고도 이런 기능을 사용할 수 있다는 것 또한 Redis의 큰 장점이다.
Redis 클러스터에서 모든 노드는 서로서로 연결된 Full Mesh 구조를 이루고있다. 모든 Master와 Replica 노드는 서로 연결되어 있으며, 가십 프로토콜을 이용해서 통신한다. 클러스터를 사용하기 위해서는 최소 세 개의 Master 노드가 필요하다.

이 구조에서 Redis에 들어오는 데이터들은 Sharding을 통해 분산된다. 애플리케이션으로부터 들어오는 모든 데이터는 해시 슬롯에 저장된다. Redis 클러스터는 총 16384개의 슬롯을 가지며, Master 노드는 슬롯을 나누어 저장한다. Master 노드가 세 개일 때 해시 슬롯이 분배될 수 있다.
노드 A는 0부터 5500까지의 해시 슬롯을, 노드 B는 5501부터 11000까지의 해시 슬롯을, 노드 C는 10001부터 16383까지의 해시 슬롯을 포함한다. 입력되는 모든 키는 슬롯에 매핑되며, 이때 'HASH_SLOT = CRC16(key) mod 16384' 알고리즘을 사용한다

해시 슬롯은 Master 노드 내에서 자유롭게 옮겨질 수 있으며, 이를 위한 다운타임은 필요없다. 따라서 새로운 노드를 추가하거나 기존 노드를 삭제할 때에는 해시 슬롯을 이동시키기만 하면 되며, 이로 인해 쉬운 확장이 가능하다.

일반적으로 세 대의 Master에 세 대의 Replica 노드를 연결하는 구성을 자주 사용하며, Replica 노드는 Master 노드의 정확한 복제본을 가지고 있다.
5) 클러스터 Failover
Sentinel과 마찬가지로 Redis 클러스터에서도 Master 노드가 다운되면 이를 위해 연결된 Replica 노드를 Master로 승격시키는 Failover가 일어난다. Sentinel 구조에서는 Sentinel 프로세스가 노드들을 감시했지만, Redis 클러스터 구조에서는 모든 노드가 서로서로 감시한다는 점에서 차이가 있다.
만약 가용성이 중요한 서비스에서 Redis 클러스터 구성을 이용할 때 노드 하나를 더 추가할 수 있는 여유가 있다면, 아무 Master에 Replica 노드를 하나 더 연결시키는 것을 추천한다. 클러스터는 Replica 노드중 하나가 다운되어 Replica 노드가 없는 Master가 생기면, Replica 노드가 두개인 마스터의 복제 노드를 그 자리에 채울 수 있기 때문이다.
A에 Replica 노드를 두 개 연결한 상태에서 B의 Replica 노드가 죽으면, A에 연결된 Replica 노드를 B의 Replica 노드로 변경시킨다. 모든 과정은 사용자의 개입 없이 클러스터 내부 통신으로 진행된다.

6) Client Redirection
클러스터 구조에서 데이터는 Master 노드에 분할되어 저장되지만, 애플리케이션은 분할된 데이터를 Client Redirection을 통해 데이터를 저장한다.
클라이언트는 Replica 노드를 포함한 모든 노드에 자유롭게 쿼리를 보낼 수 있다. 하지만 요청한 커맨드의 키가 접근하는 노드에 존재하지 않을 수 있다. 이 경우에 노드는 그 키를 가지고 있는 노드 정보를 반환하는 Redirect 메세지를 반환한다. Redis 서버 자체는 잘못된 연결에 대해 직접 데이터를 이동하거나, 명령을 전달하는 것이 아닌, 그저 올바른 주소를 전달한다.
서비스에서는 대부분 Jedis나 redis-py 등의 라이브러리를 통해 Redis를 이용한다. 이런 Redis 클라이언트는 Redirect 메세지를 받으면 올바른 주소로 연결을 변경하여 다시 같은 메세지를 보낸다. 즉, 애플리케이션은 Sharding을 생각하지 않고 아무데나 던져도 라이브러리와 Redis 서버가 알아서 다 해준다.
잘못된 주소에 저장할 경우, 잘못된 주소이기 때문에 Redirect 메시지 반환하고, 라이브러리는 제대로 된 주소에 다시 데이터를 저장한 뒤 제대로 된 주소에 물어본다.




[참고] bcho.tistory.com/654
'Database > Redis' 카테고리의 다른 글
| [Redis] redis.conf 설정 파일 (0) | 2020.10.06 |
|---|---|
| [Redis] 실습용 Redis 서버 설치 (0) | 2020.10.06 |
| [Redis] Redis 데이터 유형 (0) | 2020.10.05 |
| [Redis] NoSQL, Redis (0) | 2020.10.04 |