2021. 5. 4. 21:15ㆍGCP/원데이
1. 검색 기능 성능 측정
1) 테스트 준비
기존의 Worker 인스턴스로 머신 이미지를 만들어준다. 그리고 만든 이미지로 리전에 관계없이 2개의 새로운 인스턴스를 생성해준다. 그리고 Jenkins 배포 설정을 구성해준다. 설정을 위해서는 추가한 2개의 인스턴스에 SSH 접속을 할 수 있도록 키를 등록해주어야 한다. 하지만 GCP에서 제공하는 메타데이터에 저장을 했기 때문에 추가로 지정해줄 필요는 없다.


2) 성능 측정
Postman을 이용하여 대략 50만건의 데이터에서 4개의 키워드(영화, 재미, 감동, 스토리)를 1회차, 2회차, 3회차, 4회차, 5회차 걸린 시간 찾고 각 키워드의 응답속도 평균값을 구해본다.
여기서 데이터가 50만건 보다 더 많은 양의 데이터가 있다고 가정했을 때, 속도는 구한 값보다 더 걸리는 것을 예측할 수 있다. 그 이유는 데이터베이스가 키워드 검색에는 적합한 솔루션이 아니기 때문이다. 이러한 키워드 검색에 적합한 솔루션으로는 ElasticSearch 가 있다. 모든 성능 측정이 완료되었다면, RabbitMQ의 하단에 Purge라는 항목을 선택하여 메시지를 지워준다.

2. ElasticSearch
1) ElasticSearch 특징
ES와 일반적인 DB와의 차이로는 대표적으로 문서 저장 방식, Shard, Replica가 있다.
- 문서 저장 방식
ES의 문서 저장 방식은 DB와 동일하게 일반적인 인덱스도 남지만, 단어 단위로 잘라서 해당 단어가 어디에 위치하는지 기록을 한다. 이러한 방법을 역 색인(Inverted Index)이라고 한다. 이 경우에는 특정 단어를 찾기 위해서 모든 문서를 찾을 필요가 없어진다.

여기서 '재미'는 '재미있다'라는 단어와 같은 의미이지만 따로 기록이 되고 있다. '재미있다'를 검색을 한다면 '재미'만 들어가 있는 문서는 검색이 안되고, 반대로 '재미'를 검색한다면 '재미있다'가 들어간 문서는 검색이 되지 않는다. 이런 것을 같은 단어로 기록을 하기 위해서는 형태소 분석이라는 과정이 필요하다. 영어로된 데이터는 자동으로 지원을 해주지만, 한글로 된 데이터는 분석하기 위해서 ES에서 공식적으로 지원하는 노리(Nori)라는 플러그인을 이용하여 디테일한 역색인을 할 수 있다.
- Shard
문서 100개가 있고 하나의 공간에 저장이 되어있다면, 이를 4개로 쪼개 서로 다른 공간에 저장하는 방식을 Shard라고 한다. 그리고 분리된 각각의 Shard는 서로 다른 머신에 올라간다는 특징을 가지고 있다.
머신 위로 올라 갔을 때 하나의 머신을 노드라고 한다면, 이 노드의 성능은 노드가 가진 CPU, 메모리, 디스크의 성능에 영향을 받게 된다. 그렇다면, 이를 4개의 노드로 나눌 경우 그 만큼 더 많은 CPU, 메모리, 디스크 성능으로 더 빠른 검색을 할 수 있게 된다. 거기에 성능을 더 올릴 필요가 있다면 노드를 늘려 검색 성능을 올릴 수 있게 된다.

- Replica
Replica는 복사본으로 특정 노드에 문제가 발생하여 내려갔을 때, 해당 노드가 포함하고 있던 데이터를 다른 곳에도 저장을 하고 있는 구조이다. 남아있는 데이터가 있기 때문에 서비스가 계속 가능해진다는 장점을 가지고 있다. 중요한 부분은 동일 Replica는 동일한 노드에 저장이 되지 않는다는 점이다.
2) 클러스터 구축
일반적으로 ES 클러스터는 DB가 있는 리전에 구축을 해야한다. 현재까지 구성된 인프라에서는 Postgresql의 리전의 경우 대만이지만, 50만건의 데이터를 색인하기 위해서는 도쿄에 만드는 것이 더 빠르기 때문에 도쿄에 구축을 해준다.
기존에 별도로 도쿄에 구축된 RabbitMQ 인스턴스를 삭제해준다. (RabbitMQ는 NginX와 함께 설치되어있는 상태) 그리고 도쿄에 4개의 인스턴스를 구성해준다.

각 인스턴스에 공통적으로 설정해야하는 부분은 다음과 같다.
// 도커 설치
sudo yum install -y docker
sudo systemctl start docker
sudo chmod 666 /var/run/docker.sock
// 가상 메모리 사이즈 증가 (ES는 가상 메모리를 많이 사용)
sudo sysctl -w vm.max_map_count=262144
첫 번째 ES 인스턴스를 제외한 나머지 인스턴스에는 네트워크를 생성해주는 명령어는 없으며, 각 인스턴스의 'discovery.seed_hosts' 옵션에는 자신의 인스턴스 IP를 제외한 나머지 호스트들의 IP를 작성해주면 된다. (띄어쓰기는 생략)
-e "discovery.seed_hosts=10.146.0.4,10.146.0.6,10.146.0.5" \
- es-instance-1
docker network create somenetwork
docker run -d --name elasticsearch --net somenetwork -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={1번 IP 빼고 나머지 3개 IP}" \
-e "node.name=es01" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={1번 IP}" \
elasticsearch:7.10.1- es-instance-2
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={2번 IP 빼고 나머지 3개 IP}" \
-e "node.name=es02" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={2번 IP}" \
elasticsearch:7.10.1- es-instance-3
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={3번 IP 빼고 나머지 3개 IP}" \
-e "node.name=es03" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={3번 IP}" \
elasticsearch:7.10.1- es-instance-4
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.seed_hosts={4번 IP 빼고 나머지 3개 IP}" \
-e "node.name=es04" \
-e "cluster.initial_master_nodes=es01,es02,es03,es04" \
-e "network.publish_host={4번 IP}" \
elasticsearch:7.10.1설정이 완료된다면, 9200번 포트에 접속을 하기 위해 포트를 열어준다.

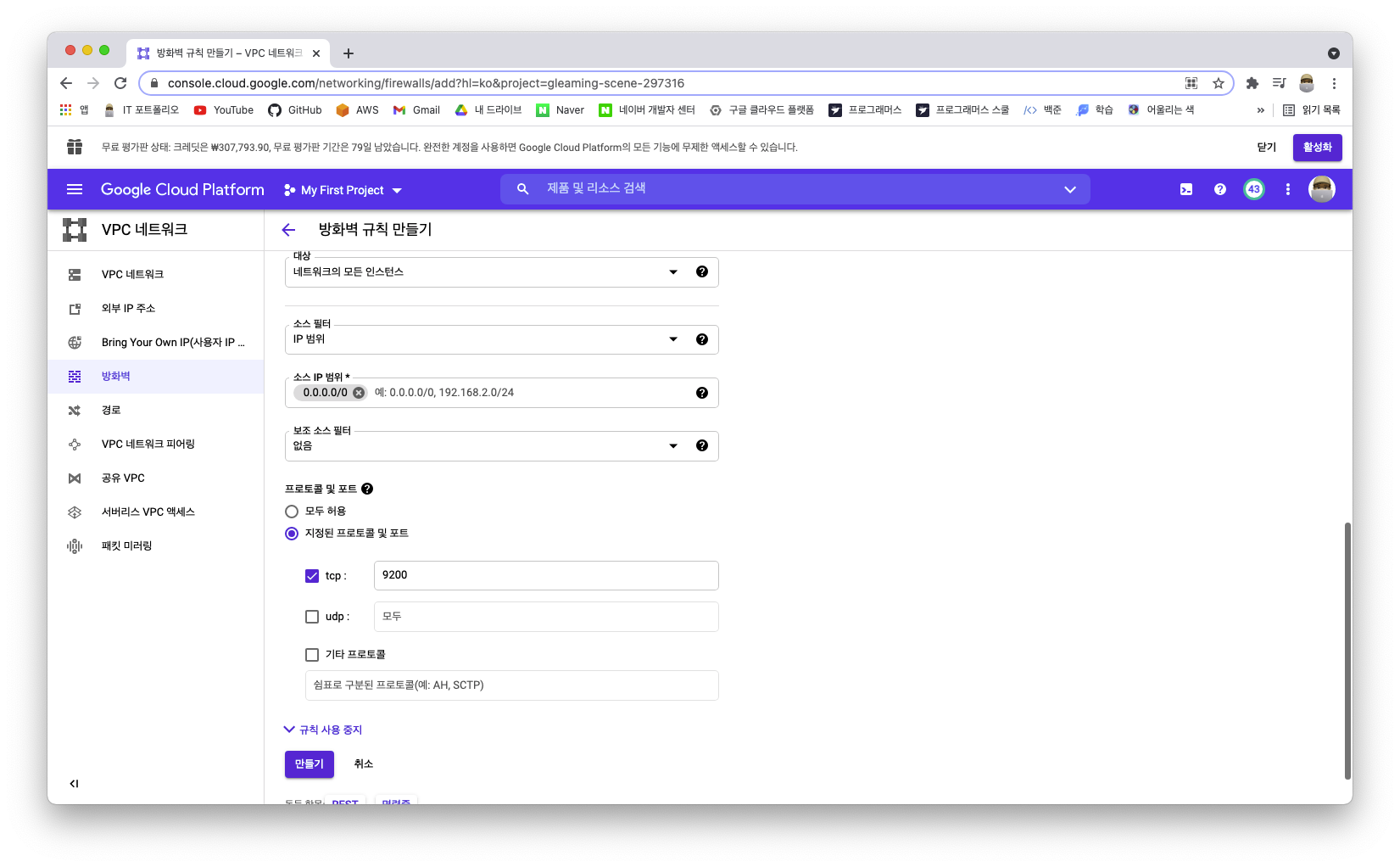
직접 인스턴스에 접속해보면 다음과 같은 화면을 볼 수 있다.

크롬에서 제공하는 'ElasticSearch Head' 확장프로그램을 이용하면 더 육안으로 편리하게 확인할 수 있다. 각 ES에서 앞의 별표 도형은 마스터 노드를 뜻한다. (일반적으로 먼저 생성된 노드가 마스터 노드)

ES에도 단점은 존재한다. DB는 데이터가 INSERT 되는 순간부터 조회가 가능하다면, ES는 조회하기까지의 약간의 딜레이가 필요하다. 내부적으로 데이터가 처리되는 과정에서 필연적으로 생기는 딜레이가 발생하기 때문이다. 하지만 매우 짧은 시간의 딜레이이므로 큰 차이는 없다. 즉, 실시간 처리가 불가능하다.
ES는 여러 노드에 분산하여 데이터를 저장하기 때문에 트랜잭션이나 롤백을 지원하지 않는다. 만약 비즈니스 로직에서 트랜잭션에 의존적인 로직이 많을 경우에는 ES의 도입은 고려해보아야 한다.
ES는 문서를 업데이트할 수 없다. 업데이트 API는 있지만, 이 API는 내부적으로 업데이트 처리가 되는 것이 아닌 데이터를 삭제했다 다시 생성하는 동작을 수행한다. 따라서 애플리케이션에서 데이터 업데이트가 많을 경우에는 ES 클러스터에 영향을 줄 수도 있다.
3) 프로젝트 수정
- build.gradle
기존의 jpa 의존성을 삭제하고 새로운 의존성을 추가해준다.
// implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'- Post.class
package com.example.io;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Data
@Document(indexName = "post")
public class Post {
@Id
private String id;
private String content;
}- ElasticSearchConfig.class
ElasticSearch에 접근하기 위한 호스트 관련 정보나 포트를 이용하여 클라이언트를 생성해준다.
package com.example.io;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
@Configuration
public class ElasticSearchConfig {
@Value("#{'${spring.data.elasticsearch.hosts}'.split(',')}")
private List<String> hosts;
@Value("${spring.data.elasticsearch.port}")
private int port;
@Bean
public RestHighLevelClient getRestClient() {
List<HttpHost> hostList = new ArrayList<>();
for (String host : hosts) {
hostList.add(new HttpHost(host, port, "http"));
}
RestClientBuilder builder = RestClient.builder(hostList.toArray(new HttpHost[hostList.size()]));
return new RestHighLevelClient(builder);
}
}
- PostController.class, PostCacheService.class
PostCacheService를 삭제해주고, 글 작성과 글 검색 기능에 대해서만 테스트를 하기 위해 해당 기능을 제외한 다른 기능들은 삭제해준다. 또한 ES에서는 findByContentContains 가 아닌 findByContent로 사용하기에 수정해준다.
package com.example.io;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
public class PostController {
@Autowired
private PostRepository postRepository;
@Autowired
private Producer producer;
@Autowired
private ObjectMapper objectMapper;
// 1. 글을 작성한다.
@PostMapping("/post")
public Post createPost(@RequestBody Post post) throws JsonProcessingException {
String jsonPost = objectMapper.writeValueAsString(post);
producer.sendTo(jsonPost);
return post;
}
// 4. 글 내용으로 검색 -> 해당 내용이 포함된 모든 글 (spring boot jpa like 구글링)
@GetMapping("/search")
public List<Post> findPostsByContent(@RequestParam String content) {
return postRepository.findByContent(content);
}
}- PostRepository.class
package com.example.io;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface PostRepository extends ElasticsearchRepository<Post, String> {
List<Post> findByContent(String content);
}- application.yml
기존의 datasource 부분을 삭제해주고, ES를 위한 호스트와 포트를 등록해준다.
spring:
config:
activate:
on-profile: prod
# datasource:
# url: jdbc:postgresql://10.140.0.5:5432/postgresql
# username: postgresql
# password: postgrespassword
# jpa:
# show-sql: false
# hibernate:
# dialect: org.hibernate.dialect.PostgreSQLDialect
# ddl-auto: update
rabbitmq:
host: 10.178.0.18
username: guest
password: guest
port: 5672
data:
elasticsearch:
hosts: 10.146.0.3,10.146.0.4,10.146.0.6,10.146.0.5
port: 92004) ES index 생성
ES Head에 들어가서 1개의 Shard에 0개의 Replica를 가진 Index를 새로 생성해준다.

만약 Index를 잘못만들었다면, Postman의 DELETE 메서드를 이용하여 삭제를 한다.

정상적으로 만들어졌다면, 다음과 같은 화면이 나온다.

5) 데이터 삽입
Artillery 스크립트를 이용하여 약 50만건의 데이터를 넣어준다.
config:
target: "http://[NginX IP]"
phases:
- duration: 60
arrivalRate: 3
name: Warm up
- duration: 120
arrivalRate: 3
rampTo: 50
name: Ramp up load
- duration: 9600
arrivalRate: 50
name: Sustained load
payload:
path: "ratings_test_50k.csv"
fields:
- "content"
scenarios:
- name: "just post content"
flow:
- post:
url: "/post"
json:
content: "{{ content }}"
# - think: 1
# - get:
# url: "/posts"
artillery run --output report.json io-test.yaml메시지가 잘 들어가는지 확인하기 위해 NginX와 같이 설치된 RabbitMQ를 확인해본다.

동시에 ES Head의 생성한 Index에서 Docs 항목이 50만 건이 될 때까지 스트레스 테스트를 진행하면 된다.

6) 검색 기능 테스트
모든 데이터의 삽입이 이루어지고나서 검색을 해본다. 그 결과로는 500에러가 발생할 수 있는데, Worker 인스턴스에 SSH 접속을 하여 nohup.out 파일을 열어보면 'Elasticsearch exception ... from + size must be less than or equal to: [10000] ...' 로그가 찍혀있는것을 확인할 수 있다.
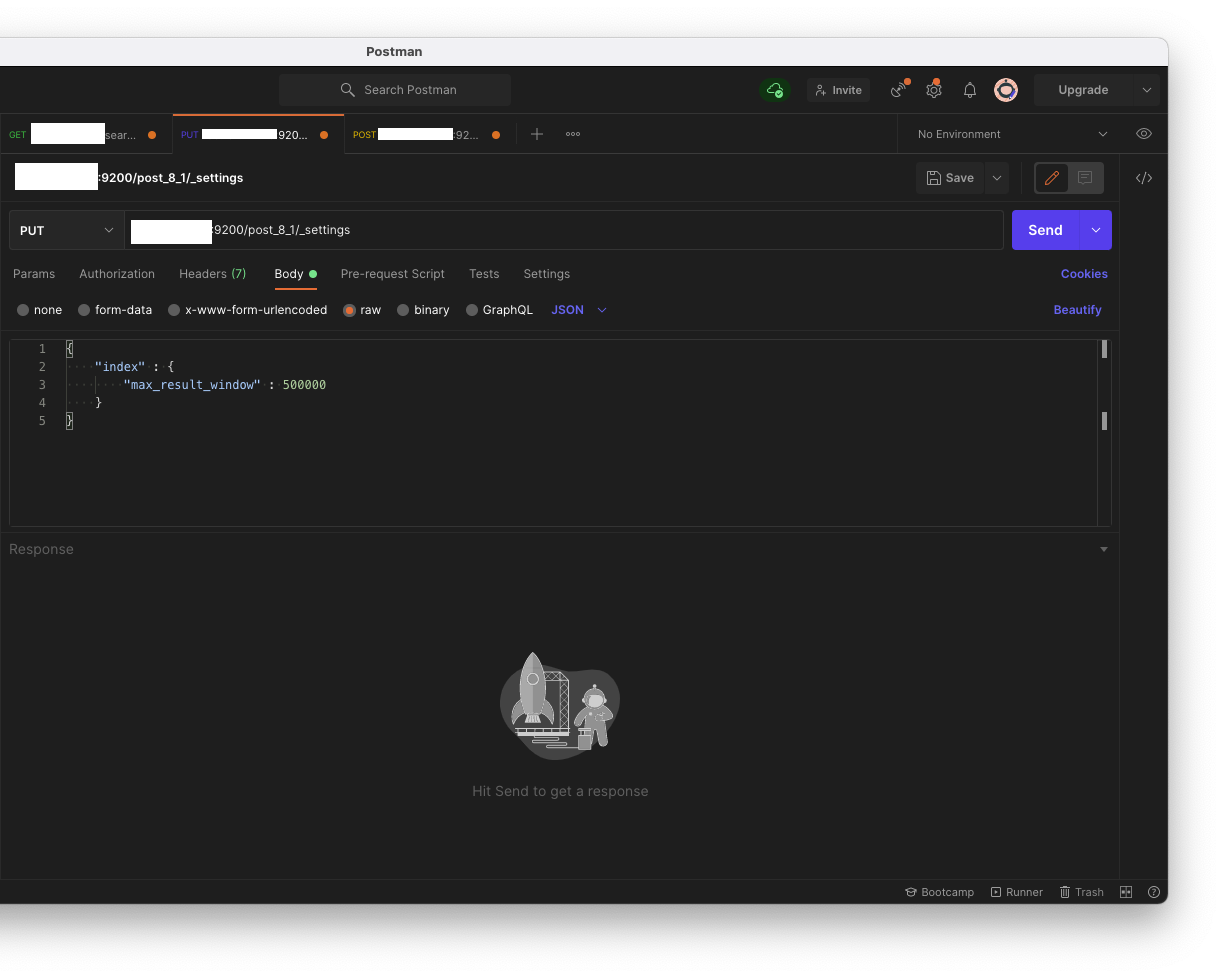
ES는 기본적으로 10000개까지만 반환하도록 기본적으로 설정되어있기에 에러가 발생한다. 이 에러를 해결하기 위해서는 검색을 통해 인덱스 설정을 바꿔야한다. 설정은 Postman으로 해결이 가능하다. ('[ES IP]/[Index 명]/_settings')

다시 검색을 시도하면, 결과는 나오지만 DB를 사용하여 요청했을 때보다 안좋은 결과가 나오는 것을 볼 수 있다. 설정한 Shard가 1개 일 때, 키워드가 너무 많은 문서에 매칭이 될 경우에 역 인덱스의 효과가 제대로 발휘되기 어렵다. 하지만 Shard를 더 늘렸을 경우에는 더 좋은 결과가 나올 수 있다.
7) Shard 추가
더 좋은 결과를 얻어내기 위해 Shard를 8개로 늘려본다.

Shard를 늘리게 되면 노드 1은 2와 6번 Shard, 노드 2은 3과 7번 Shard, 노드 3은 1과 5번 Shard, 노드 4는 0과 4번 Shard를 가지게 되는 것을 확인할 수 있다. 따라서 특정 키워드를 포함한 문서를 검색하고자 한다면 각 노드별 Shard에서 검색하게 된다.
이렇듯 문서를 나누어서 검색하기 때문에 검색 성능은 역색인과 합쳐서 Shard를 통해 향상될 수 있게 된다.

여기서 기존에 생성한 post에 있는 문서를 post_shard_8로 옮겨야 하기 때문에 ES에서 지원해주는 Reindex API를 이용한다. 모든 문서가 옮겨지면, ES Head의 Index의 Docs 항목이 업데이트가 되는 것을 볼 수 있다.
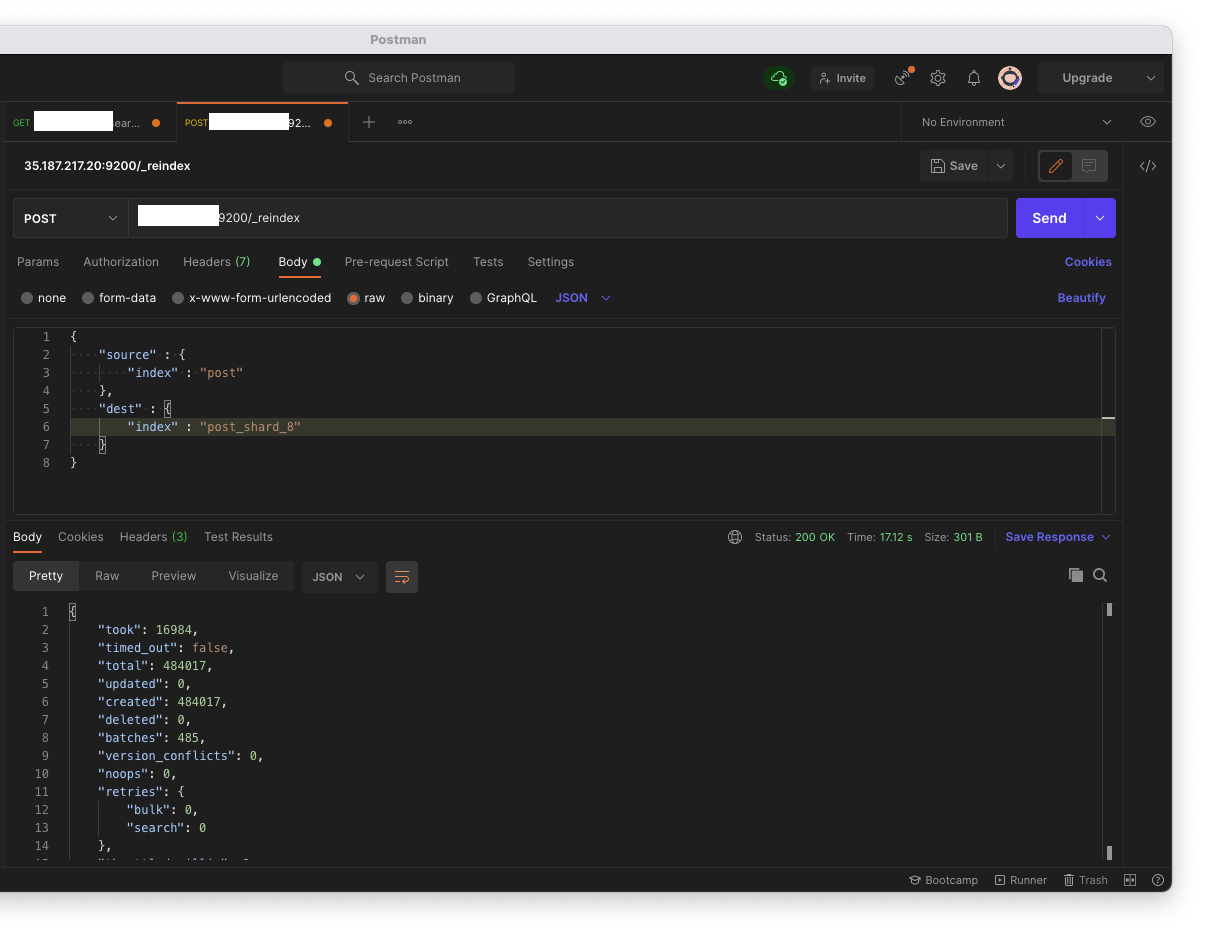
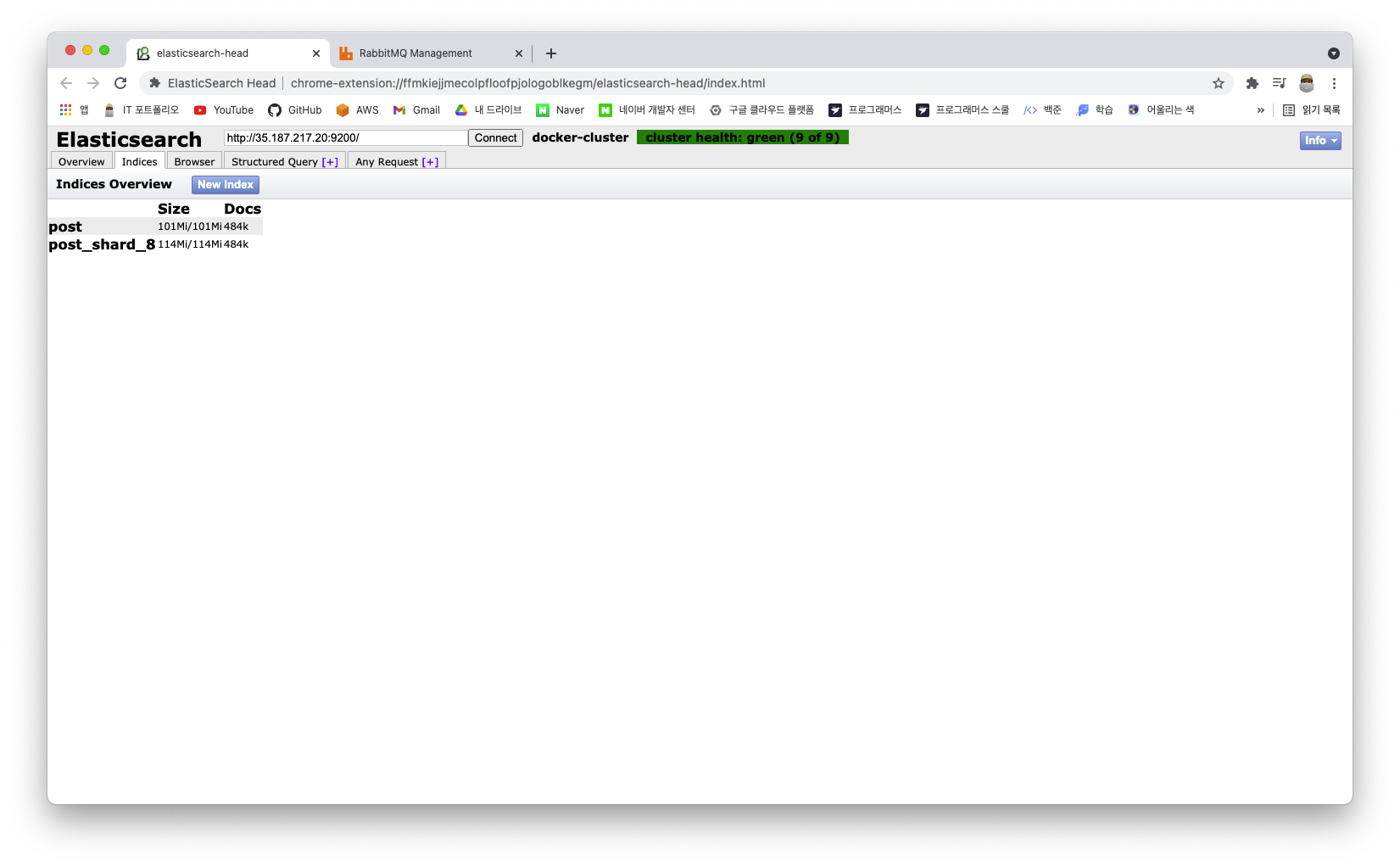

새로 'post_shard_8' Index를 생성한 만큼, 프로젝트에도 수정사항을 반영해주어야 한다. 그리고 Jenkins에서 배포를 해준다.
package com.example.io;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Data
@Document(indexName = "post_shard_8")
public class Post {
@Id
private String id;
private String content;
}또한 'post' 인덱스에 'max_result_window' 사이즈를 새로 설정해주었던 것처럼 'post_shard_8'의 사이즈도 설정해준다.

마지막으로 검색 성능을 확인을 해보면 이전보다는 만족스러운 결과물을 확인할 수 있다. 하지만 무작정 Shard의 수를 늘린다고 해서 성능이 좋아지지는 않는다. 결국 하나의 노드에 Shard가 여러 개 있더라도 노드에 있는 자원을 공유해서 사용하기 때문에 Shard가 너무 많아지면 성능이 더 떨어질 수 도 있다.
8) Replica 추가
Replica를 추가한 Index를 생성해준다.

추가를 하면, 노드 2의 2번 Shard는 노드 1이 가지고 있고, 노드 1의 3번 Shard는 노드 2가 가지고 있는 형태로 이루어지는 것을 확인할 수 있다.

성능 테스트를 위해서 Reindex API로 문서를 옮기고 'max_result_window'의 값과 프로젝트의 Post 클래스를 수정 후 Jenkins로 배포해준다.
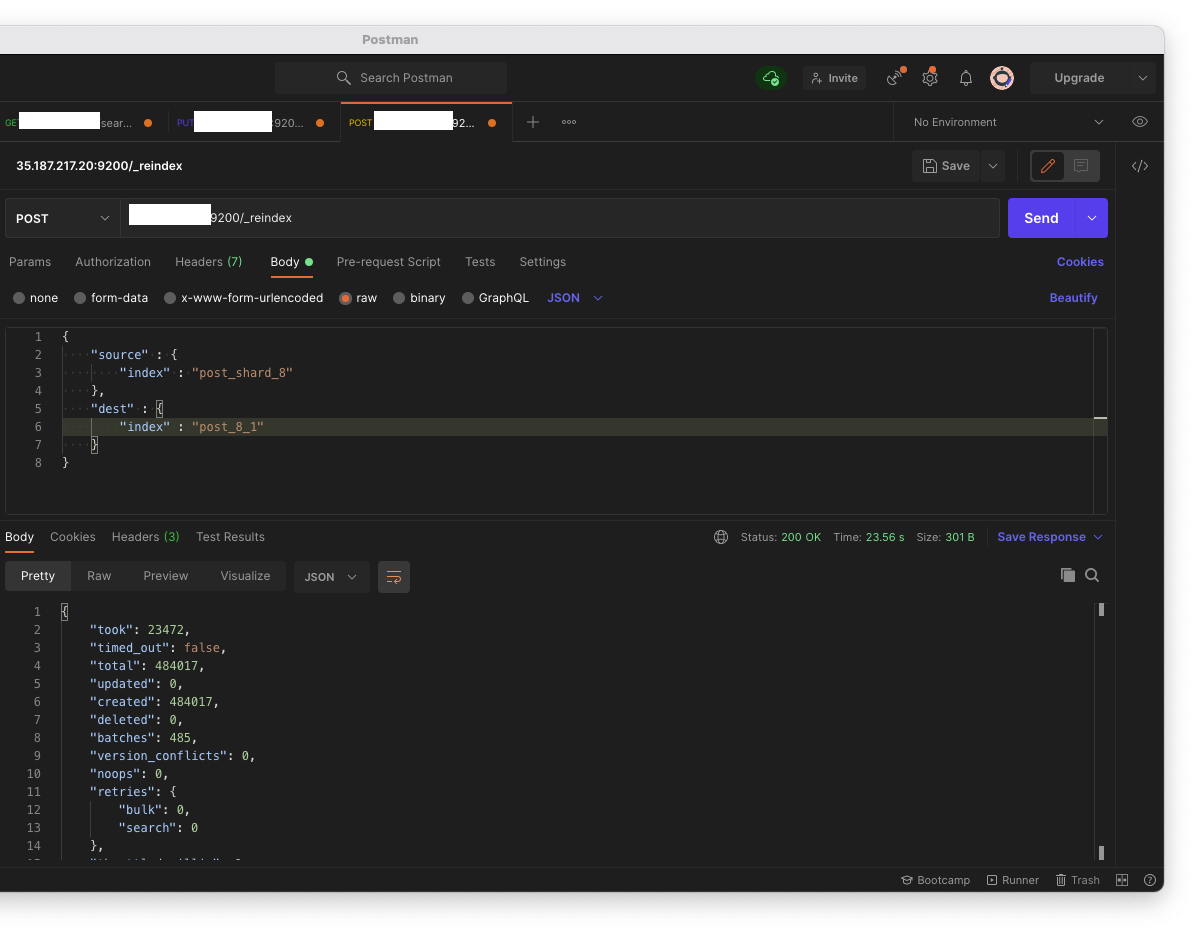
package com.example.io;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Data
@Document(indexName = "post_8_1")
public class Post {
@Id
private String id;
private String content;
}마지막으로 검색 기능을 시도를 하면 Shard 8개, Replica 1개 일 때의 검색 성능은 Replica가 없을 때보다는 성능이 대략 비슷하게 나오는 것을 확인할 수 있다.
Replica의 동작을 확인하기 위해 노드 2를 제거해본다. ES 인스턴스 SSH에 접속하여 컨테이너를 멈춰본다.
docker ps
docker stop [컨테이너 ID]멈추고 어느 정도의 시간이 흐른 뒤 ES Head를 살펴보면, 노드의 개수가 줄어들어 검색 시간이 느려지지만, 응답이 제대로 돌아오는 것을 확인할 수 있다.

9) 요약
- Shard를 1개만 허용하는 경우에는 DB보다 성능이 떨어질 수 있다. 단, 문서의 개수가 적을 때에는 오히려 성능이 잘 나온다.
- Shard를 8개를 허용했을 경우 문서의 개수가 많을 때와 적을 때의 성능이 전반적으로 모두 향상이 된다.
- Shard 8개, Replica 1개를 허용했을 경우 문서의 개수가 많을 때 성능이 조금 덜 나오지만 문서의 개수가 적을 때에는 거의 동일한 결과가 나온다.
'GCP > 원데이' 카테고리의 다른 글
| [GCP 원데이] RabbitMQ (0) | 2021.05.03 |
|---|---|
| [GCP 원데이] 서버가 죽는 이유, Message Queue (0) | 2021.05.03 |
| [GCP 원데이] I/O 바운드 애플리케이션 (2) (0) | 2021.05.03 |
| [GCP 원데이] I/O 바운드 애플리케이션 (1) (0) | 2021.05.01 |