2021. 5. 3. 18:08ㆍGCP/원데이
1. 서버가 죽는 이유
1) 서버가 죽었다 란?
'서버가 죽었다'라는 표현은 두 가지로 해석이 가능하다.
- 일부 요청이 실패한다. (대부분의 경우)
- 모든 요청이 실패한다.
모든 요청이 실패하는 경우에는 네트워크 장애 혹은 서버 자체의 문제로, 높은 트래픽으로 행이 걸렸을 때 발생한다. 이는 자연스럽게 해소할 수도 있으며, 애플리케이션 재시작을 통해 해결할 수도 있다.
CPU 바운드 애플리케이션에서는 CPU 사용을 많이 필요로 하는 해시 연산을 다량 요청했을 때 실패했다. DB I/O 애플리케이션에서는 DB를 사용하는 게시글 INSERT와 SELECT를 다량 요청했을 때 실패했다.
이러한 많은 요청이 들어오면, 기다렸다가 처리하여 문제가 발생하지 않는다고 생각할 수 있다. 그럼에도 500에러 혹은 타임 아웃 에러가 발생하는 이유는 톰캣의 사용자 요청 처리 방법 때문이다.
2) 톰캣의 기본 설정
톰캣에서 사용자의 요청은 우선 큐(FIFO)에 들어가게 된다. 톰캣은 이 요청은 놀고 있는 쓰레드가 있을 때 해당 쓰레드가 받아서 처리를 하는 구조로 되어있다.
큐의 기본 사이즈는 100이며 요청을 처리하는 쓰레드의 기본 숫자가 200개 이다. 여기서 쓰레드가 처리하는 양보다 들어오는 요청이 더 많을 경우, 그 때부터 들어오는 요청은 큐에서 대기를 하게 된다. 그리고 그 요청에 대한 응답 시간이 점점 길어지게 된다.
이러한 과정에서 큐 사이즈를 모두 채우고 나서도 요청이 들어오거나 큐에 들어오기 시작한 요청이 처리되는 데까지 30초를 넘으면(타임아웃) 해당 요청부터 실패하게 된다.
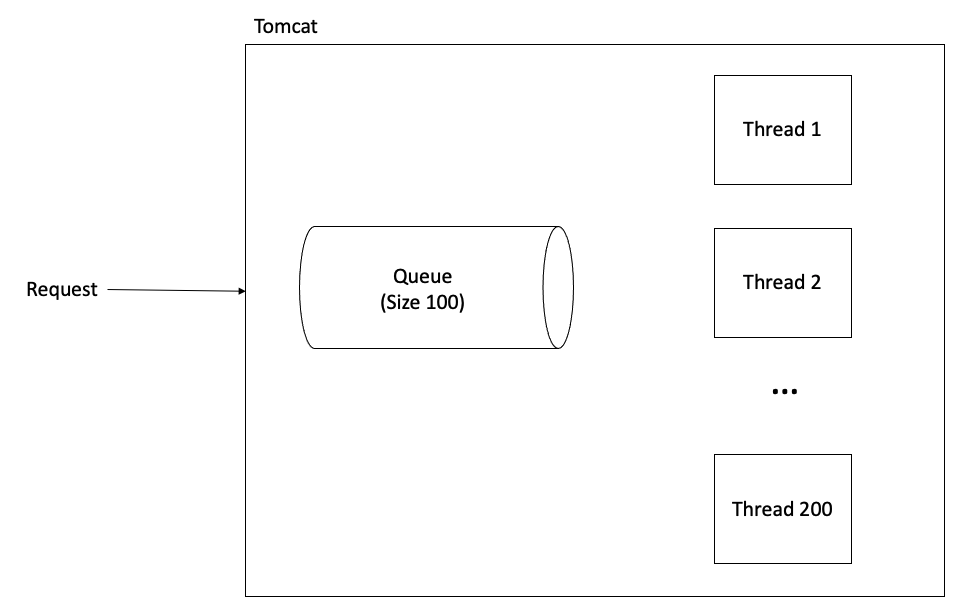
물론, 톰캣의 큐 사이즈, 타임아웃, 쓰레드 풀의 사이즈 모두 변경이 가능하다. 하지만 이 숫자들을 늘려도 요청이 빠르게 처리되지는 않는다.
큐 사이즈를 늘린다면, 많은 요청을 저장했다가 처리하는 방식으로 일시적으로 사용자가 요청 실패를 경험하는 시간을 늦출 수는 있다. 하지만 타임아웃이 발생한다면 큐에 저장된 요청들은 모두 실패하게 된다.
여기서 타임아웃을 길게 잡는다면, 실패가 되었어야할 요청들이 큐에 계속 쌓이는 결과를 가져올 수 있다.
다음으로 쓰레드의 경우 CPU를 서로 공유하고 해시 연산은 CPU에서 이루어지기 때문에 한 쓰레드가 CPU를 사용할 경우 다른 쓰레드들은 차례가 오기까지 기다려야하기에 수를 늘려도 문제가 해결되지는 않는다. DB도 마찬가지로 다량의 INSERT문이 동시에 들어온다면, DB에 모두 기록하기 위해 점점 느려진다.
즉, 다량의 요청이 들어오면 모든 쓰레드는 일하기 시작하고 큐에 요청이 쌓이다가 일부 요청들은 큐의 사이즈를 넘어서 버려지고, 일부 요청은 타임아웃이 발생하여 버려지게 된다.
3) 구조 변경
기존의 구조가 다음과 같다면
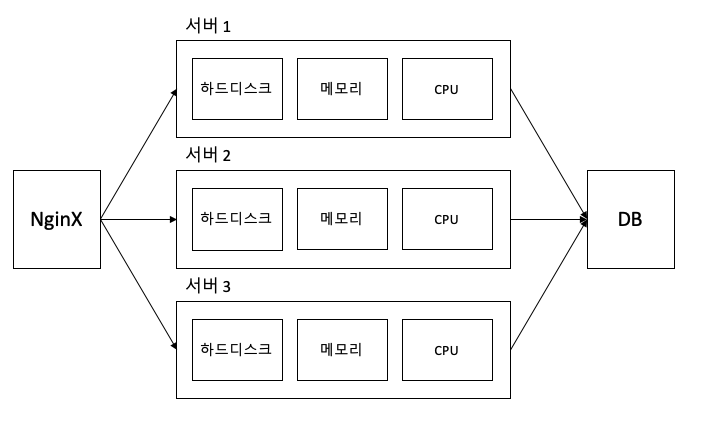
DB 앞에 큐를 추가하여 사용자의 글 작성 요청을 모두 저장했다가 처리를 할 수 있도록 구성한다. 이 때 톰캣의 큐가 아닌 RabbitMQ라는 별도의 메시지 큐를 이용한다.
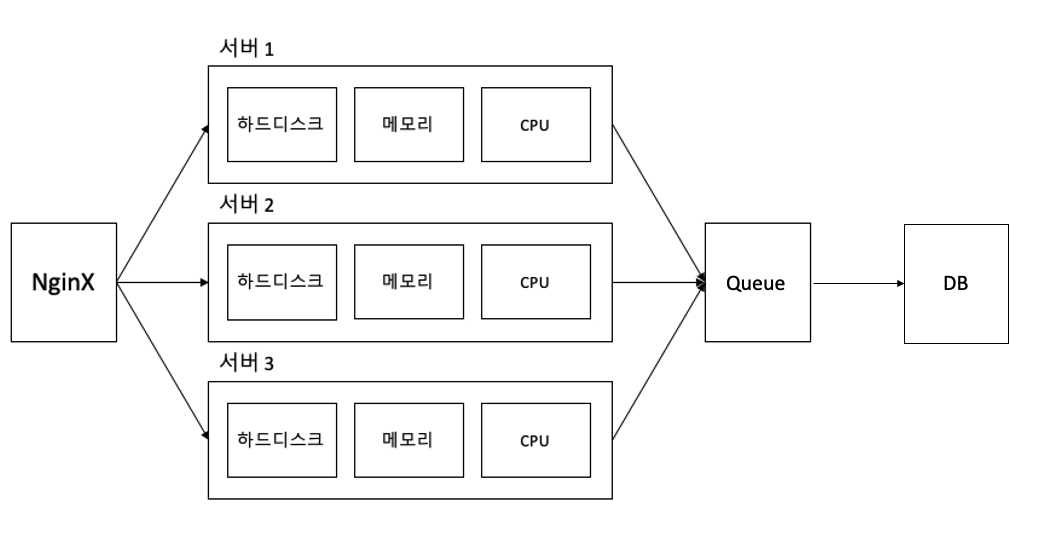
물론, 큐에서 바로 DB에 넣는 것이 아니다. 우선 글 작성 요청이 들어온다면 컨트롤러에서 바로 메세지 큐에다 저장한다. 그리고 사용자의 글작성 요청은 큐로 들어가게 되며 해당 스레드는 다음 요청을 받을 준비를 한다. I/O 바운드 애플리케이션의 다른 부분에서는 해당 큐에 있는 글 작성 요청을 뽑아 DB에 넣어준다.
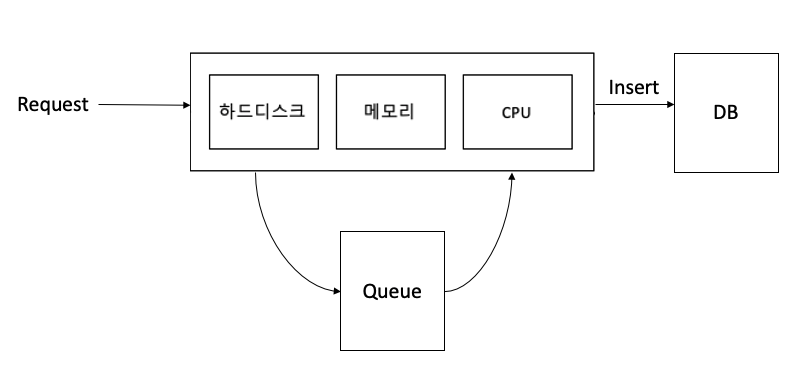
톰캣 큐에서 처리하는 방법과 별도의 큐를 두어 처리하는 것의 차이가 있다. 톰캣의 큐는 어떠한 내용을 저장하고 처리하는데 특화되어있지 않다. 특히 큐에 저장된 데이터는 도중에 톰캣이 종료될 경우 메모리에 저장된 데이터이기 때문에 없어져버린다. 반면 MQ에서는 디스크에 저장하는 등 다양한 옵션을 제공한다.
2. Message Queue
1) 비동기성
MQ는 비동기적이다. 이 때 글 작성 명령을 저장했다가 처리하는 것은, DB 속도와 무관하게 메시지를 누락없이 저장했다가 처리할 수 있다는 특징이 있다. 또한 DB에 INSERT하는 시간보다 MQ에 메시지를 넣는 시간이 훨씬 짧다는 장점을 가지고 있다.
2) 의존성
MQ는 애플리케이션간의 의존성을 제거할 수도 있다. A라는 애플리케이션에서 B라는 애플리케이션으로 API를 호출하여 데이터를 전달해준다면 A는 B에 의존성이 생기게 된다. B가 배포를 하거나 죽는 순간 A에서 B로 전달하려던 데이터는 없어져버린다. 하지만 중간에 MQ를 두게 된다면, B가 죽더라도 데이터가 유실되지 않게 된다.
3) 이중화
물론 큐도 소프트웨어이기에 장애가 발생할 수도 있다. 큐가 위치한 머신에서 물리 장애가 발생하거나 네트워크에서 장애가 발생할 가능성도 있다. 이를 위한 해결책으로는 큐의 이중화이다. 여러 개의 큐를 사이에 두고 큐 사이에서 데이터를 지속적으로 동기화하여 한쪽 큐에 장애가 발생해도 전체 큐 서비스에는 영향이 없도록 구성할 수 있다.
4) 실패 시 재실행 가능
큐에서 메시지를 꺼내어 특정 로직을 실행시킬 때 에러가 발생한다면, 해당 메시지를 다시 큐에 넣을 수도 있다. 이러한 부분은 MQ에 신뢰성을 부여해준다. (데이터가 절대로 유실되지 않는다는 점은 아니다.)
5) 확장성
하나의 큐에 여러 개의 애플리케이션이 동시에 메시지를 넣거나 뺄 수 있다. 애플리케이션이 스케일 아웃을 하더라도 MQ는 동일하게 하나만 존재해도 된다는 뜻이다.
'GCP > 원데이' 카테고리의 다른 글
| [GCP 원데이] 검색 기능 성능 측정, ElasticSearch (0) | 2021.05.04 |
|---|---|
| [GCP 원데이] RabbitMQ (0) | 2021.05.03 |
| [GCP 원데이] I/O 바운드 애플리케이션 (2) (0) | 2021.05.03 |
| [GCP 원데이] I/O 바운드 애플리케이션 (1) (0) | 2021.05.01 |